|
|
|
Замеры времени и профилирование Автоматизируйте замеры времени. В большинстве систем существуют команды, позволяющие выяснить, сколько времени работала программа. В Unix такая команда называется time:
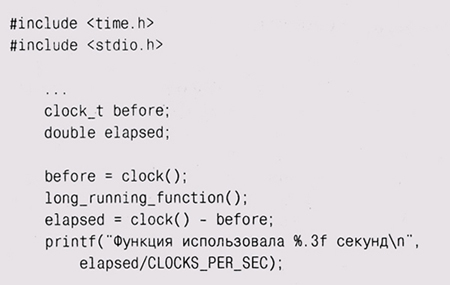
Если в вашей системе нет команды time или вы хотите замерить время работы отдельно взятой функции, не так трудно создать себе оснастку для таких замеров — по аналогии с тестовой оснасткой. В С и C++ существует стандартная функция clock, которая сообщает, сколько процессорного времени программа использовала до текущего момента. Ее можно вызвать перед интересующей вас функцией и после нее и таким образом вычислить время ее исполнения процессором:
Используйте профилировщик. Не считая такого надежного и достоверного способа, как замер времени исполнения программы, самым важным инструментом для анализа производительности является система для генерации профилей. Профиль (profile) -- это измерение того,,где именно программа "тратит время". Некоторые профили предоставляют список всех функций, количество вызовов каждой из них и долю потребляемого каждой функцией времени от общего времени исполнения программы. Другие показывают, сколько раз было выполнено каждое выражение. Выражения, которые выполняются часто, сильнее влияют на время исполнения, а те, которые не выполняются никогда, скорее всего, являются бесполезным или неадекватно оттестированным кодом. Профилирование — эффективный способ поиска горячих точек (hot spots), или критических мест программы, то есть функций ши^фрагмен-тов кода, которые расходуют львиную долю всего времени исполнения программы. Однако же интерпретировать результаты профилирования надо с достаточной степенью осторожности. Из-за изощренности компиляторов, сложности организации кэширования и работы с памятью, а также из-за того, что сам процесс профилирования влияет на производительность, статистические показатели в профилях могут быть только приблизительными. В 1971 году в работе, где впервые был представлен термин "профилирование", Дон Кнут написал, что, "как правило,-менее 4 % программы поглощают более половины от всего времени исполнения". Принимая во внимание это замечание, можно сделать вывод о способах применения профилирования: с его помощью определяются участки программы, поглощающие большую часть времени работы, в них вносятся улучшения, и процесс повторяется еще раз для поиска новых критических мест. Выясняется, что после одной-двух подобных итераций характерных "горячих точек" не остается. Профилирование обычно включается специальным флагом или опцией компилятора. Программа выполняется, и после этого показываются результаты работы профилировщика. В Unix таким флагом является, как правило, -р, а профилировщик называется prof:
12234768552: Total number of instructions executed
Очевидно, что в затратах времени доминируют две функции: strchr и strncmp, причем обе вызываются из strstr. Итак, Кнут ориентирует нас правильно: небольшая часть программы поглощает большую часть времени ее исполнения. При первом профилировании программы очень часто выясняется, что лидирующие в профиле две-три функции поглощают половину времени и более, как в приведенном случае, и, соответственно, становится сразу же ясно, на чем сконцентрировать внимание. Концентрируйтесь на критических местах. Переписав st rst r, мы еще раз выполнили профилирование для spamtest и выяснили, что теперь 99.8 % времени тратит собственно strstr, хотя в целом программа и стала работать быстрее. Когда одна функция является таким явным узким местом программы, существует только два способа исправить положение: улучшить саму функцию, применив более эффективный алгоритм, или/ке избавиться от этой функции вообще, переписав всю программу. Мы выбрали второй способ — переписали программу. Ниже приведены первые несколько строк профиля работы программы sparest, использующей последнюю, наиболее быструю реализацию isspam. При этом общее время работы программы существенно уменьшилось, критической точкой стала функция memcmp, a isspam стала заш'мать более существенную долю от общего времени. Эта версия гораздо сложнее предыдущей, однако эта сложность окупается с лихвой благодаря отказу от использования strlen и strchr в isspam и замене sees % cum% cycles instructions calls function strncmp на memcmp, которая тратит меньше усилий и» обработку каждого байта.
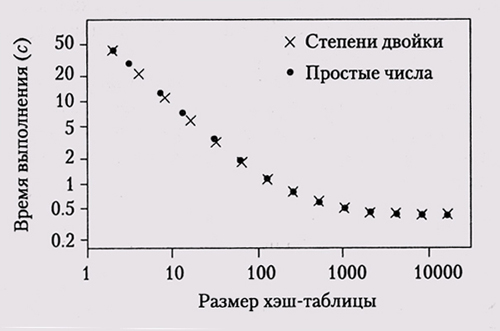
Весьма поучительно будет потратить некоторое время на сравнение счетчиков циклов и количества вызовов различных функций в двух профилях. Отметьте, что количество" вызовов strlen упало от нескольких миллионов до 652, a strncmp и memcmp вызываются одинаковое количество раз. Обратите внимание и на то, что isspam, которая сейчас взяла на себя и функцию st rch r, умудряется обойтись гораздо меньшим количеством циклов благодаря тому, что она проверяет на каждом шаге только нужные образцы. Изучение чисел может раскрыть и многие другие детали хода выполнения программы. "Горячая точка" нередко может быть уничтожена или, по крайней мере, существенно "охлаждена" гораздо более простыми способами, чем мы применили для спам-фильтра. Когда-то давным-давно профилирование Awk показало, что одна функция вызывается примерно миллион раз — в таком цикле: ? for (j ='i; j < MAXFLD; j++) Выполнение этого цикла, в котором поля очищались перед считыванИем каждой новой строки ввода, занимало почти 50 % от всего времени исполнения. Константа MAXFLD — максимальное количество полей в строке ввода — была равна 200. Однако в большинстве случаев использования Awk реальное количество полей не превышало двух-трех. Таким образом, огромное количество времени тратилось на очистку полей, которые никогда и не устанавливались. Замена константы на предыдущее значение максимального количества полей дало выигрыш в скорости 25 %. Все исправления свелись к изменению верхней границы цикла: for (j = i; j < rnaxfld; j++) Постройте график. Особенно удачным получается представление замеров производительности в виде графиков. Графики помогут более наглядно представить информацию о влиянии изменения параметров, сравнить алгоритмы и структуры данных, а иногда и указать на неожиданное поведение программы. Графики длин цепочек для нескольких хэш-мультипликаторов в главе 5 явно продемонстрировали преимущества одних мультипликаторов перед другими. На представленном ниже графике показано влияние размера массива хэш-таблицы на время исполнения С-версии программы ma rkov; в качестве вводимого текста использовались Псалмы (42 685 слов, 22 482 префикса)., Мы поставили два эксперимента. В первой серии запусков программа использовала размеры массивов, которые являлись степенями двойки — от 2 до 16 384; в другой версии использовались размеры, которые являлись максимальным простым числом, меньшим каждой степени двойки. Мы хотели посмотреть, приведет ли использование простых чисел в качестве размеров массивов к ощутимой разнице в производительности.
Упражнение 7-2 Вне зависимости от того, есть на вашей машине команда time или нет, используйте clock или getTime для создания собственного измерителя времени. Сравните его результаты с системным временем. Как влияет на результаты другая активность на машине? Упражнение 7-3 В первом профиле st rch г вызывалась 48 350 000 раз, a st rncmp — только 46 180 000 раз. Объясните это различие. |
|
|
|